
Some data cannot be freely shared. This section focuses on personal data and privacy issues. Other cases might be witness protection, data revealing precise locations of endangered species or vulnerable archaeological sites and data with potential for dual use – civil and military with possible abuse by terrorists.
Human participants are often willing, sometimes even eager to participate in and thus contribute to scientific research. But they may care about their privacy. Trust between researchers and study participants has to be created and needs to be maintained. Study participants may not want their personal data to be (re-)used by others whom they do not trust, and/or for purposes which they do not approve.
We provide general guidance followed by links to applicable regulations and other resources with more detailed coverage of some topics. The Max Planck Digital Library does not provide legal advice. Professional legal advice should be sought if you are unsure about legal requirements placed on your (planned) research.
What are Personal Data?

Personal data are data that can be attributed to a specific identifiable person. These data can consist of the following three categories:
- Direct identifiers can be unambiguously linked to a single person, e.g. name, address, phone number, social security number (and similar), email address (if revealing name and possibly employer) but also unique profession (e.g. CEO of a named company), photos (also MRI scans) or voices.
- Indirect identifiers can reveal the identity of a person taken together in the same dataset, and possibly combined with information from other sources. Indirect identifiers include birth date, age, place of residence/zip code, rare profession or income for example.
The potential for identification is currently much higher than decades ago, because a lot of information is readily and often freely available online. For studies covering a named small area, local knowledge and personal information about other people also have to be taken into account. - Special personal data (also referred to as “sensitive data”): racial/ethnic origin, political opinion, religious or philosophical beliefs, trade union membership, sexual activity and/or orientation, health data, genetic and biometric data.
Direct identifiers should be replaced as soon as possible by pseudonyms during the research process (pseudonymization). Special personal data should only be collected if relevant for the given study. Generally, data minimization implies that data that are not needed to answer a study question should not be collected in the first place.
Ethics Approval
Some research will require prior approval by a Research Ethics Committee or Institutional Review Board. Many German universities have an ethics committee at the medical faculty/university hospital – see Association of Medical Ethics Committees in Germany – which can also assess research projects by Max Planck researchers. If this option isn’t available, the MPG project leader can contact the Ethics Council of the Max Planck Society (MPG Intranet) for an ethics vote.
Further resources: Ethics Committee of the German Society for Psychology and psychological faculties of universities, Ethics Committee of the German Society for Linguistics, Ethics Committee of the German Society for Educational Science.
Informed Consent
Informed consent by study participants and data anonymization are two key aspects for generating, processing and (possibly) sharing data from research on human subjects. Anonymization has to be balanced with data utility. If sufficient data anonymization compromises data utility, data may still be shared under restricted access.
Before giving consent, scientific studies participants must be informed which personal data will be collected, archived, and potentially shared, and which steps will be taken to safeguard anonymity and confidentiality. If personal (sensitive) data are collected, it has to be specially mentioned. Participant information should include the project purpose as well as benefits and possible risks for the study participants.
All documents should be written in a language understandable to participants, and be concise and complete. Participants must have the opportunity to ask questions, and must be provided with contact details for questions that may arise at a later stage.
If these requirements are met, a participant can make a voluntary informed choice to accept or refuse to cooperate. Consent will often be specific, e.g. linked to the stated purpose of a scientific study.
It must be possible to withdraw consent at any later stage, as easily as giving consent and without providing reasons. Participants must be clearly informed that a refusal to participate or later withdrawal of consent will not lead to any consequences.
Written or oral consent? Written consent is preferable, as it facilitates documentation and allows clarification of the extent of consent. However, written consent may not be possible in some cases, e.g. informal research settings or participants wary of formal documentation. Oral consent may be acceptable, but should ideally be recorded (video or audio) or be obtained in the presence of a witness.
So far, it has been assumed that study participants are capable of and legally entitled to giving consent. If this is not the case, consent has to be obtained from parents/guardians (for children) or legal representatives (in case of mental illness or dementia). To the extent possible, participants should still be asked, with assent registered and dissent respected. It also has to be justified why a study needs to include participants unable to provide consent.
Research without consent may be necessary if participants cannot be informed in advance, because knowledge of the underlying research question would invalidate the method. Such research is possible, but will be subject to rigorous ethical review, ensuring that three criteria are met:
- clear value and benefit of the research
- no alternative research design possible to address the research question
- no or very minimal risk of harm to the participant
Data Anonymization
Anonymization aims at data that can no longer be linked (unambiguously or tentatively) to an individual person. Sufficiently anonymized data are no longer considered personal data. Anonymization is irreversible and thereby distinct from reversible pseudonymization, where data and personal identifiers are stored separately and can be combined with each other again.
Anonymization techniques may include
- removal of direct identifiers, as well as indirect identifiers
- generalization of data, providing ranges rather than precise values or not revealing details: e.g. age 20-30, 30-40, 40-50, … , only first three digits of zip codes, region rather than village
- top-encoding rare values or outliers: e.g. age 80 or higher, monthly net income 7.500€ or higher, three or more children, “other” for rare mother tongue in a given context
- distorting data by adding some “noise” – precluding identification of individuals while not affecting statistical analysis and interpretation of data
Qualitative data (e.g. interviews and their transcripts) pose additional challenges: Personal identifiers may occur throughout a document rather than in a structured and predictable way, study participants may reveal information about third parties. Such documents need to be carefully edited, names might be replaced by roles (husband, friend, teacher) or by he/she. Modifications should be clearly marked, for example as “names changed”.
Search and replace functions of software can be helpful but should be used with care and manually checked: some replacements might be unnecessary, while other personal identifiers are overlooked (e.g. due to typos). Editing video or audio documents can be technically challenging but can be realized by blurring faces in videos or adding bleeping to audio files. In some cases, it may be better to share only transcripts.
Anonymization is always a trade-off between removing all potential identifiers and keeping the data scientifically significant.
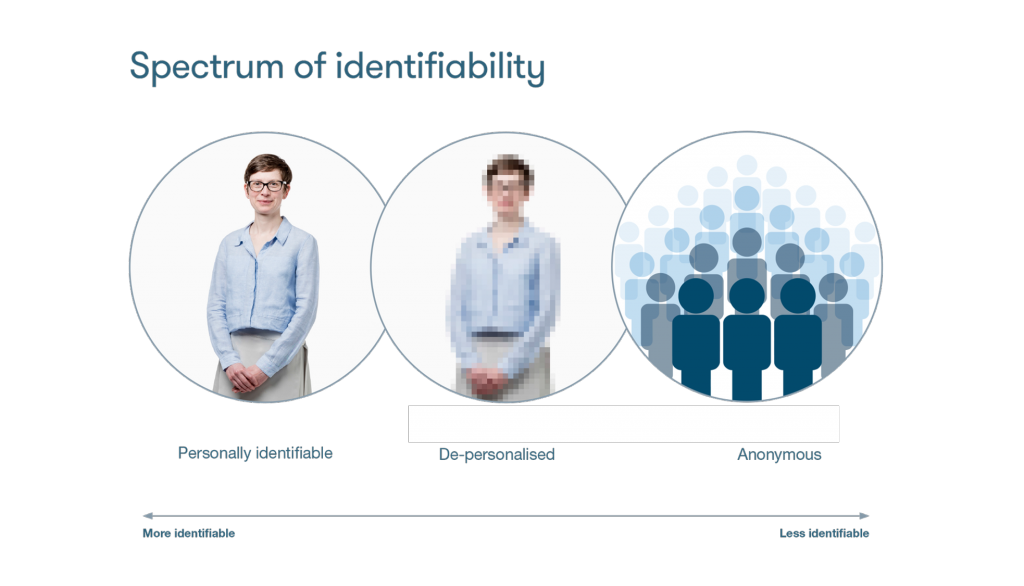
Aggregated data (summary statistics of large datasets not revealing individual data points) offer guaranteed anonymity. The usability of aggregated data may be limited, both in verifying some research conclusions and addressing new research questions.
Nevertheless, it is possible to estimate the assignment to a person. In the case of anonymisation, this traceability should also be taken into account.
If there are still concerns about anonymized data, it might be useful to insist on signing a data use agreement. This agreement should specify that users will:
- use such data only for a defined scientific purpose (relevant and consistent with informed consent from study participants).
- refrain from attempts to re-identify study participants.
- refrain from sharing data with third parties.
More Information, Guidelines, and Tools
Data Protection within the Max Planck Society
- Central Data Protection Office of the Max Planck Society and contact address
- Local Data Protection Officers at each Max Planck Institute
- Information side on human research by the CDPO
- Data Protection Collection by the CDPO
- Max-Planck-Schutzbrief on data protection issues, four times a year
Legal Framework and Guidelines for Biomedical Research
- General Data Protection Regulation (GDPR)
- Bundesdatenschutzgesetz (new version 2018, German implementation of EU regulations)
- WMA Declaration of Helsinki – Ethical Principles for Medical Research Involving Human Subjects
Guideline for Good Clinical Practice
- International ethical guidelines for health-related research involving humans CIOMS (Council for International Organizations of Medical Science)
- Oviedo Convention: protecting human rights in the biomedical field
- Belmont Report: Ethical Principles and Guidelines for the Protection of Human Subjects of Research (U.S. Department of Health and Human Services)
See also: Dankar, F. K., Gergely, M., & Dankar, S. K. (2019). Informed Consent in Biomedical Research, in: Computational and Structural Biotechnology Journal 17, 463-474. doi:10.1016/j.csbj.2019.03.010 (Mini Review on historical developments and current practice for Big Data)
Online Practise and Tools
- Amnesia by OpenAIRE: Data Anonymization Algorithms Tool which satisfys GDPR Guidelines
- CESSDA (Consortium of European Social Science Data Archives): Anonymisation Training
- QualiAnon (Qualiservice, University of Bremen): Anonymisation Tool
- Stiftung Datenschutz: Practice Guide to Anonymising Personal Data
- UK Data Service: Text Anonymisation Helper Tool
Further Reading
European Commission (14th November 2018): Ethics and data protection.
Kreutzer, T., & Lahmann, H. (2019) Rechtsfragen bei Open Science. Ein Leitfaden. Hamburg University Press.
Katrin Schaar and Heidi Schuster (28th February 2019): Kommentierte Vorlage für Einwilligungserklärungen. Entwickelt im Projekt CASTELLUM, https://max.mpg.de/Zentrale-Beauftragte/Datenschutz/_layouts/15/WopiFrame2.aspx?sourcedoc=%7b65e8b131-15d0-4522-9f25-5663468a3dd9%7d&action=embedview&wdStartOn=1 (only in German).
RatSWD German Data Forum (2020): Data Protection Guide – 2nd fully revised edition, RatSWD Output 8 (6), Berlin, German Data Forum (RatSWD), doi:10.17620/02671.57.
RatSWD German Data Forum (2022): Best-Practice Research Ethics, https://www.konsortswd.de/ratswd/best-practice-forschungsethik/. [only in German]
Stiftung Datenschutz (2022): Basic Rules for the Anonymisation of Personal Data.
Stiftung Datenschtz (2022): Practice Guide to Anonymising Personal Data.
UK Data Service (2021): Legal and ethical issues.
Latest News about Legal and Ethical Aspects
- Research Data within the New Rules of Conduct for Good Scientific Practice by the Max Planck Society

- Discussion Series: Human Research Data in Practice on 24th May 2022

- Discussion Series: Human Research Data in Practice on 25th January 2022